יצא לי לאחרונה לטפל בבעיות ביצועים בספריה שלי. מבלי להכנס ליותר מדי פרטים, הספריה היא (בין השאר) ספריית Server המבוססת על WebSockets, וככזאת היא מטפלת בClientים מחוברים.
ברגע שהClient מצליח להתחבר לServer, הServer צריך להקצות לו מזהה ייחודי (הנקרא גם SessionId) - זהו מספר רנדומלי שלם בין 0 ל$ 2^{50} $ (לא כולל הקצוות. יכול להיות שהקצה הוא לא בדיוק $ 2^{50} $ אלא משהו שאני לא זוכר כרגע, אבל זה לא מהותי להמשך הפוסט).
אילוסטרציה:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
publicclassServer
{
privatereadonly Random mRandom = new Random();
privatereadonly ClientProxyContainer mClientContainer = new ClientProxyContainer();
privateconstlong MAX_RANDOM_SIZE = 2 >> 50;
publicvoidOnNewClient(IConnection connection)
{
ClientProxy clientProxy = new ClientProxy(connection);
(פישטתי קצת את הסיפור, כעקרון צריך שהClientContainer יבחר את הSessionId, באופן שיצא חד-חד-ערכי. בנוסף, אין Overload לRandom שמקבל long, אבל אנחנו נתעלם מהבעיות האלה כיוון שהן לא מהותיות בהקשר של הבעיה)
הספריה כמובן מקבלת את הClientים בצורה א-סינכרונית, מה שאומר שכשClient מתחבר, מתעורר Thread מהThreadPool (באמצעות מנגנון הIOCP) ומתחיל לטפל בו. בדרך כלל הסיפור עבד בסדר גמור, אבל במקרי קיצון (מספר גדול מאוד של קליינטים או הרבה חיבורים/ניתוקים בו זמנית), יצא מצב שכל הקליינטים שהתחברו קיבלו את אותו SessionId שערכו היה 0. (למי שקורא את מה שכתוב בסוגריים - במימוש הראשון לא וידאתי שאכן הSessionId חד-חד-ערכי. במידה והייתי מוודא זאת, במקום לקבל SessionId=0 בכל הקליינטים, השרת היה נתקע בלולאות אינסופיות)
דיבגתי את הקוד וראיתי שRandom מחזיר במקרה קיצון זה 0 תמיד. חיפשתי באינטרנט על כך, ומצאתי פוסט בבלוג של MSDN מ2009. בפוסט זה מציינים שRandom אינו Thread-safe והוא ממומש בצורה שגורמת לכך שאם הוא נקרא ממספר Threadים במקביל, הוא יחזיר 0. בפוסט זה מציעים שני פתרונות לבעיה זו. הפתרון הראשון שהוא מאוד פשוט הוא להשתמש במנגנון נעילה:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
publicclassServer
{
privatereadonly Random mRandom = new Random();
privatereadonly ClientProxyContainer mClientContainer = new ClientProxyContainer(
privatereadonlyobject mLock = newobject();
privateconstlong MAX_RANDOM_SIZE = 2 >> 50;
publicvoidOnNewClient(IConnection connection)
{
ClientProxy clientProxy = new ClientProxy(connection);
שימו לב שאנחנו נועלים רק בפעם הראשונה בכל Thread כשנוצר הRandom הפנימי. הבעיה בפתרונות אלה שמוצעים בפוסט המדובר היא שמדובר במשתנה סטטי. עדיף לעבוד עם משתנה שהוא גם פר Instance.
למזלנו קיים בFramework טיפוס בשם ThreadLocal המאפשר את הסיפור הזה. (למי שלא מכיר, זהו טיפוס שעוטף את LocalThreadStorage בצורה נוחה)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
publicclassThreadSafeRandom
{
privatereadonly ThreadLocal<Random> mRandom;
privatereadonlyobject mLock = newobject();
privatereadonly Random mSeedGenerator = new Random();
publicThreadSafeRandom()
{
mRandom = new ThreadLocal<Random>(() => GetRandom());
}
private Random GetRandom()
{
int seed;
lock (mLock)
{
seed = mSeedGenerator.Next();
}
Random random = new Random(seed);
return random;
}
public Random Random
{
get
{
return mRandom.Value;
}
}
}
publicclassServer
{
privatereadonly ClientProxyContainer mClientContainer = new ClientProxyContainer();
privatereadonly ThreadSafeRandom mThreadSafeRandom = new ThreadSafeRandom();
privateconstlong MAX_RANDOM_SIZE = 2 >> 50;
publicvoidOnNewClient(IConnection connection)
{
ClientProxy clientProxy = new ClientProxy(connection);
מדי פעם יוצא לנו לכתוב ספריות Reusable. (נקרא מדי פעם גם "תשתיות תוכנה")
כדי שספריות אלה יהיו איכותיות, כדאי שיהיה בהן בין השאר Logging, כדי שנוכל לקבל חיווי על מה הספריה עושה ובאיזה שגיאות היא נתקלה.
לצערנו אין בFramework כלי Log סביר, ולכן בדרך כלל אנו פונים לספריה חיצונית שעושה זאת בצורה מצטיינת. בד”כ log4net היא הספריה הנבחרת לצרכים אלה. אלא שלעתים מתכנת המשתמש בספריה שלנו משתמש כבר בתשתית Logים אחרת. (למשל NLog, Enterprise Library וכו’)
הדבר הזה מכריח את המשתמש להוסיף Reference לספריית Logם של הספריה, ומכריחה אותו בדרכים לא דרכים לגרום לספריית הLogים של הספריה להשתמש בספריית הLogים של האפליקציה, כדי שהLogים ירשמו למקומות הנכונים.
למרבה המזל, הדבר אפשרי, מאחר ותשתית Logים המכבדת את עצמה בד”כ מאפשרת מנגנון של Appenderים - מקומות אליהם לכתוב את הLog, ולכן ניתן ליצור Appender שיפנה למנגנון Logים אחר.
היו בעבר כבר כמה ניסיונות לגשר על פער זה: הרבה ספריות מכילות ממש אבסטרקטי לLog לו יש מימושים בDllים חיצוניים, למשל לCastle יש ממשק בשם ILogger שנראה כך:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
publicinterfaceILogger
{
bool IsDebugEnabled { get; }
bool IsErrorEnabled { get; }
bool IsFatalEnabled { get; }
bool IsInfoEnabled { get; }
bool IsWarnEnabled { get; }
ILogger CreateChildLogger(String loggerName);
voidDebug(String message);
voidDebug(Func<string> messageFactory);
voidDebug(String message, Exception exception);
voidDebugFormat(String format, params Object[] args);
voidDebugFormat(Exception exception, String format, params Object[] args);
voidDebugFormat(IFormatProvider formatProvider, String format, params Object[] args);
voidDebugFormat(Exception exception, IFormatProvider formatProvider, String format, params Object[] args);
voidError(String message);
voidError(Func<string> messageFactory);
voidError(String message, Exception exception);
voidErrorFormat(String format, params Object[] args);
voidErrorFormat(Exception exception, String format, params Object[] args);
voidErrorFormat(IFormatProvider formatProvider, String format, params Object[] args);
voidErrorFormat(Exception exception, IFormatProvider formatProvider, String format, params Object[] args);
voidFatal(String message);
voidFatal(Func<string> messageFactory);
voidFatal(String message, Exception exception);
voidFatalFormat(String format, params Object[] args);
voidFatalFormat(Exception exception, String format, params Object[] args);
voidFatalFormat(IFormatProvider formatProvider, String format, params Object[] args);
voidFatalFormat(Exception exception, IFormatProvider formatProvider, String format, params Object[] args);
voidInfo(String message);
voidInfo(Func<string> messageFactory);
voidInfo(String message, Exception exception);
voidInfoFormat(String format, params Object[] args);
voidInfoFormat(Exception exception, String format, params Object[] args);
voidInfoFormat(IFormatProvider formatProvider, String format, params Object[] args);
voidInfoFormat(Exception exception, IFormatProvider formatProvider, String format, params Object[] args);
voidWarn(String message);
voidWarn(Func<string> messageFactory);
voidWarn(String message, Exception exception);
voidWarnFormat(String format, params Object[] args);
voidWarnFormat(Exception exception, String format, params Object[] args);
voidWarnFormat(IFormatProvider formatProvider, String format, params Object[] args);
voidWarnFormat(Exception exception, IFormatProvider formatProvider, String format, params Object[] args);
}
יש גם פרויקט ממש מגניב בשם Common.Logging שכתב Appenderים המאפשרים להמיר כתיבה לכל תשתית Logים מוכרת לתשתית Logים מוכרת אחרת. הם אפילו תומכים במספר גרסאות של תשתיות logים, למשל הם מאפשרים לכתוב מגרסה 1.1 של log4net לגרסה 1.2 של log4net!
אלא שכל הפתרונות הנ”ל לוקים בבעיה ההתחלתית: אנו מכריחים את המשתמש להוסיף Reference לתשתית Logים שהוא לא רוצה להשתמש בה ישירות.
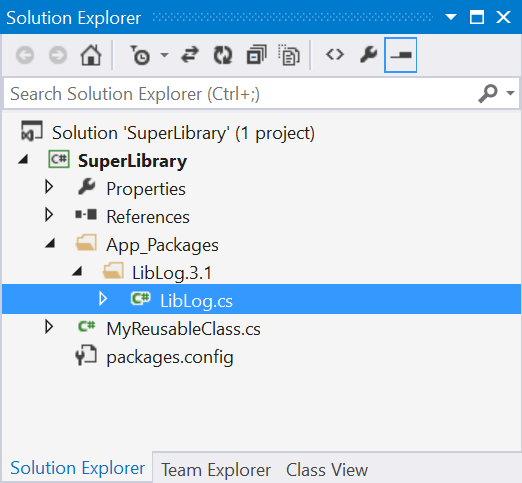
אז על מה הטיפ? מסתבר שיש פרויקט בשם LibLog הפותר את הבעיה הזו. השימוש הוא כנ”ל: מתקינים מהNuGet חבילה בשם LibLog, ויש Logים בפרויקט. אלא שלא נוסף Reference:
ואז נוסף לנו קובץ cs לcsproj:
עם namespace בשם SuperLibrary.Logging (כאשר SuperLibrary הnamespace של הספריה שלנו). קובץ זה מכיל הרבה ממשקים ומימושים שלהם.
בקובץ זה יש מחלקה בשם LogProvider תחת הnamespace הנ”ל המספק ממשק בשם ILog שנראה כמו לוג סטנדרטי:
אבל איך עובדת הכתיבה לLog? הכתיבה עובדת עם ספריה פופולרית, בהנחה והReference שלה זמין. איך זה עובד? הספריה בודקת בReflection האם אחת מהספריות הפופולריות זמינה ובמידה וכן, היא משתמשת בה בReflection. לדוגמה, כך נראה חלק מהמימוש הlog4netי של הספריה: (חתכתי את הרוב, אבל תסתכלו בקובץ)
בעזרת הספריה של vtortola אני כותב הודעות Json לClientים. הבעיה: הספריה שלי יכולה לכתוב הודעות מכמה Threadים לClient, אבל vtortola לא מרשה לכתוב לClient ביותר מThread אחד בו זמנית.
בעיה זו ניתן לפתור בעזרת טכנולוגיות שונות המממשות את הPattern של Consumer/Producer. למשל בעזרת TPL Dataflow הפתרון נראה כך:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
publicclassMyConnection : IDisposable
{
privatereadonly TcpClient mClient;
privatereadonly ActionBlock<string> mActionBlock;
publicMyConnection(TcpClient client)
{
mActionBlock = new ActionBlock<string>(x => InnerSend(x));
mClient = client;
}
privateasync Task InnerSend(string json)
{
try
{
StreamWriter streamWriter = new StreamWriter(mClient.GetStream());
await streamWriter.WriteAsync(json)
.ConfigureAwait(false);
}
catch (Exception ex)
{
// Log ex
}
}
publicvoidDispose()
{
mActionBlock.Complete();
mActionBlock.Completion.Wait();
}
}
הסבר קצר: ActionBlock היא מחלקה המקבלת בConstructor פונקציה שמקבלת T ומחזירה Task. עבור כל אובייקט שנכנס לActionBlock, מורצת הפונקציה. הActionBlock דואג לכמה פעמים יכולה הפונקציה לרוץ במקביל: באופן דיפולטי יכול לרוץ בו-זמנית רק Task בודד. (ניתן לשנות זאת ע”י העברת פרמטרים בConstructor)
המשמעות היא שבכל פעם שנכנס אובייקט לActionBlock, הוא נכנס לתור. כשמגיע תורו, נוצר Task (ע”י הפונקציה). רק לאחר שTask זה מסתיים, תרוץ הפונקציה עבור האובייקט הבא בתור. זה מבטיח לנו שThread אחד בלבד פורק את ההודעות בו-זמנית.
נתקלתי בבעיה, כיוון שTPL Dataflow לא נתמך בFramework 4.0 ובMono.
שאלתי בStackOverflow, ומסתבר שניתן לממש ActionBlock בסיסי בעזרת rx. למי שלא מכיר את rx, זהו Framework גאוני לתכנות Event driven המאפשר לא מעט יכולות (ביניהן גם LINQ), שמאפשר להשתמש בהרבה עקרונות מתמטיים, כגון קומפוזיציה ועוד. הרצאתי על rx לא אחת, אני ממליץ לקרוא על זה באינטרנט ולראות הרצאות בנושא. (יש מימושים לrx בשפות הבאות: C#, C++, Java, Ruby, Python, Clojure, JavaSciprt ועוד!)
אני מסביר את הפתרון כי אני חושב שהוא מעניין. (אם אתם יכולים להשתמש בTPL Dataflow זה כמובן עדיף!)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
public class ActionBlock<T>
{
privatereadonly ISubject<T> mSubject = new Subject<T>();
מה שאנחנו רואים זה את הדבר הבא: יש לנו במחלקה Member מסוג ISubject<T>, זהו אובייקט שניתן להפיץ אליו אירועים מצד אחד, ולהרשם לאירועים שלו מצד שני. אנחנו מפיצים אליו אירועים בפונקציה Post (ע”י קריאה לפונקציה OnNext).
בConstructor אנחנו יוצרים Task שמייצג את הסיום של הBlock (הTask ששמו Completion מסתיים אחרי שקוראים לComplete והסתיימה ריצת הTaskים עבור כל איברי התור).
יוצרת IObservable<IObservable<Unit>>. הפונקציה Observable.FromAsync היא פונקציה שמקבלת [פונקציה המייצרת Task]. היא יוצרת Observable קר (זהו Observable שמתחיל לייצר אירועים רק לאחר שנרשמו אליו) המסתיים לאחר שהTask הנוצר מהפונקציה הפנימית מסתיים.
השורה
1
.Concat()
היא קריאה לפונקציה Concat. הפונקציה Concat משטחת את הIObservable<IObservable<Unit>> לIObservable<Unit> באופן הבא: היא נרשמת ראשית לIObserable הראשון שחוזר מהIObservable<IObservable<Unit>>. לאחר מכן, לאחר שהIObservable הראשון מסתיים, היא נרשמת לIObservable השני עד שהוא מסתיים וכו’. בסופו של דבר הIObservable השטוח מפיץ את כל התוצאות הנ”ל, ומסתיים כאשר הIObservable הפנימי האחרון מסתיים.
השורה
1
.ToTask();
היא קריאה למתודה ToTask. מתודה זו יוצרת Task מIObservable נתון. Task זה מסתיים כאשר הIObservable מסתיים וערכו הוא הערך האחרון של הIObservable. אלא שפונקציה זו מחזירה Task שהוא Faulted במידה והIObservable לא הפיץ אף ערך. כדי לתקן זאת, אנחנו קוראים לCount:
1
.Count();
Count זהו אופרטור המחזיר IObservable המסתיים כאשר הIObservable המקורי מסתיים, ומפיץ ערך בודד: מספר האיברים שהופצו ע”י הIObservable המקורי.
זהו מימוש נחמד. מה אם נרצה לקבוע את מספר הThreadים המטפלים במקביל למספר אחר? נוכל לעשות זאת ע”י אופרטור אחר ששמו Merge. אופרטור זה הוא אופרטור נוסף המשטח IObservable<IObservable> לIObservable בודד המפיץ את ערכים של כל הIObservableים הפנימיים. לאופרטור זה overload המקבל int ששמו maxConcurrent - זהו מספר המאפשר להחליט לכמה IObservableים פנימיים של הIObservable הגדול ניתן להרשם בו-זמנית.
לכן הקוד יכול להראות כך:
1
2
3
4
5
6
7
8
publicActionBlock(Func<T, Task> action, int maxConcurrent)
אחד הדברים שקרו בFramework 4.5 הוא ששדרגו את העבודה עם Reflection.
זה בא לידי ביטוי בכל מיני Extension Methods חדשים, ביניהם הExtension Methods שיש לעבודה עם Custom Attributes במחלקה CustomAttributeExtensions והExtension Methods במחלקה RuntimeReflectionExtensions, מתודות חדשות שנוספו לכל מיני MemberInfoים (כגון CreateDeleage של MethodInfo) ובעוד מספר Featureים חדשים (למשל TypeInfo).
אחד הדברים שקרו הוא שנוספה אפשרות לCustomized Reflection.
למה הכוונה?
לא אחת יוצא לנו לכתוב איזשהו מנגנון המרה משלנו שממיר אובייקטים מסוג אחד לאובייקטים מסוג אחר באמצעות Reflection. למשל, סירלוז אובייקטים לפורמט אחר (בינארי/Xml/Json), או העתקת Properties מאובייקט אחד לאובייקט אחר, וכו’.
בד”כ המנגנונים האלה עוברים על הProperties של הType שאנחנו מעוניינים לעבד בReflection ועושים איתם משהו. מה קורה אם אנחנו מעוניינים שמנגנון כזה יתייחס (או לחלופין לא יתייחס) לProperty מסוים? בד”כ בכדי לציין זאת, אנחנו שמים Attribute מעל הProperty שמציין, למשל, שאת הProperty הזה אנחנו רוצים לסרלז. (לפעמים אנחנו מציינים עוד הגדרות בAttribute, כמו באיזה שם לסרלז את הProperty, אבל לא נתייחס לזה כרגע)
כלומר, בד”כ המנגנונים האלה שאנחנו כותבים שרצים על המחלקות בReflection, ניזונים מAttributeים שהמשתמש שם על הTypeים והMemberים שלו.
מה הבעיה?
הבעיה היא שלפעמים אנחנו מעוניינים גם לתמוך בטיפוסים שכבר קיימים, ואין לנו אפשרות לערוך אותם. הדוגמה הקלאסית, היא הדוגמה של Dictionary - הרבה פעמים נכתוב איזשהו מנגנון שיודע לעבוד עם מחלקות של המשתמש, אבל הוא לא ידע להתמודד עם Dictionary, משום שלטיפוס KeyValuePair אין Attributeים שמציינים שצריך, למשל, לסרלז את הKey ואת הValue שלו.
בעיה נוספת היא שלפעמים אנחנו מעוניינים שהמנגונים יזהו Properties דינאמיים, למשל, נניח שטיפוס מסוים מחזיק איזשהו Dictionary, ואנחנו מעוניינים שהמנגנון יתייחס לאיברים בDictionary כאילו הם Properties של האובייקט.
כבר בעבר ניסו לפתור בעיה זו, למשל ע”י שימוש בTypeDescriptor המאפשר לנו לערוך Typeים בצורה Customized. הבעיה היא שמדובר בשפה מקבילה לReflection, וקשה לעבוד עם שתיהן בו זמנית.
RelectionContext נוסף בFramework 4.5 לבקשת צוות MEF, והוא נותן מענה לחלק מהבעיות.
אז מה זה בכלל? ReflectionContext היא מחלקה אבסטרקטית היושבת בmscorlib תחת הnamespace ששמו System.Reflection עם המתודות הבאות:
יש כאן שלוש מתודות: MapAssembly הממפה Assembly אחד לAssembly אחר, MapType הממפה TypeInfo אחד לTypeInfo אחר וGetTypeForObject המקבלת אובייקט ומחזירה את הType המתאים לו. (אני לא ארחיב כאן על TypeInfo, אבל בגדול מדובר בApi יותר נוח לType שנוסף בFramework 4.5)
הרעיון הוא שהמנגנונים שנכתוב יעבדו עם ReflectionContext, ואז במקום לקרוא לGetType ישירות על האובייקטים שמועברים למנגנון שלנו, כמו שנהגנו עד כה, נקרא לGetTypeForObject וכך נקבל תצוגה של הType של האובייקט כפי המנגנון מעוניין לראות אותו.
באופן דומה, קיימות המתודות שממפות TypeInfo לTypeInfo וAssembly לAssembly, שהמנגנון שלנו ישתמש בהן במקומות שבהם הוא מקבל Type או Assembly, כדי לראות את אלה בתצוגה שרלוונטית אליו.
שימו לב שאפשרות מעניינת היא שהמנגנון שנכתוב יאפשר להזריק אליו מבחוץ ReflectionContext, וכך למשתמש תהיה שליטה על הMetadata שהמנגנון שלנו רואה.
איך משתמשים בזה?
לצורך השימוש הנפוץ, נכתבה מחלקה בשם CustomReflectionContext היושבת בdll חדש בשם System.Reflection.Context.dll.
נוכל לרשת ממנה בכדי לפתור את שתי הבעיות שציינתי בהתחלה: (יש לה מספר פונקציות שנוח לדרוס)
הפתרון של הבעיה הראשונה: יהיה לנו נוח לדרוס את המתודה GetCustomAttributes בכדי להשפיע על איזה Attributeים יש לType שנקבל.
בקשר לבעיה השנייה: לצערי, מסתבר יותר מסובך לפתור בעיה זו משחשבתי. להלן השימוש שאליו התכוון המשורר:
לCustomReflectionContext יש מתודה בשם AddProperties שניתן לדרוס על מנת להוסיף Properties דינאמיים לType. אלה Properties קבועים לכל הInstanceים של הType ולא Properties לפי Instance.
למשל, נניח שיש לנו את הטיפוס הזה שלא שייך לנו
1
2
3
4
5
publicclassPerson
{
publicstring FirstName { get; set; }
publicstring LastName { get; set; }
}
אז נוכל להוסיף לו Property דינאמי בשם FullName בצורה הבאה:
אחת היכולות שנוספו בC# 5.0 היא יכולת לא כל כך מפורסמת והיא הבאה:
מדובר בשלושה Attributeים המאפשרים לנו לקבל אינפורמציה על הקריאה למתודה:
CallerMemberNameAttribute - זהו Attribute שאם נשים מעל פרמטר מסוג string, נקבל את שם הMember שקרא למתודה שלנו (לקונבנציית השמות, ראו את הפירוט המלא בMSDN)
CallerFilePathAttribute- אם נשים Attribute זה מעל פרמטר מסוג string, נקבל את שם הקובץ (הcs) שבו נכתבה השורה שקוראת למתודה שלנו
נגדיר מתודה, מעל אחד הפרמטרים נשים את הAttribute ונדאג לתת לפרמטר גם default value. מה שיקרה זה שאם נקרא למתודה בלי לציין את הdefault value, הקומפיילר ישתול את מה שהAttribute מבטיח שנקבל, במקום לשתול את הערך הדיפולטי שקבענו.
הערה: שימו לב שהFilePath שאנחנו מקבלים הוא מה שהקומפיילר רואה כשהוא מקמפל את הקריאה שלנו למתודה. מאחר ואנחנו מקמפלים בד"כ על מכונות בילדים, אם אתם מאיזשהי סיבה רוצים להשתמש בCallerFilePathAttribute, תדאגו לחלץ מהPath הזה איזשהו path רלטיבי או משהו שלא תלוי באיפה התוכנה התקמפלה (למשל, בעזרת המחלקה Path).
כעקרון אני מעודד לא להשתמש בCallerFilePath וCallerLineNumber. באשר לCallerMemberName, הוא כן שימושי ואני אכתוב על זה בהמשך.
בעיה שיצא לי להתקל בה מספר פעמים היא הבעיה הבאה: נתונה לנו סדרה של איברים כך שלכל איבר יש אינדקס, ולצורך העניין האינדקסים ממוינים בסדר עולה (ממש). אנחנו מעוניינים לאגד לקבוצות איברים הנמצאים בסדרה עם אינדקסים עוקבים.
בבעיה הזאת אפשר להתקל במספר מקומות:
קריאת קובץ, סינון כל השורות שעונות על קריטריון מסוים (למשל, כל השורות שכתובות באנגלית), ויצירת קובץ חדש בו יש פסקה המכילה כל רצף כנ”ל של שורות:
1
2
3
4
5
6
7
8
9
10
11
string[] lines = File.ReadAllLines(fileLocation);
var relevantLines =
lines.Select((x, i) => new
{
Line = x,
Index = i
})
.Where(x => IsRelevant(x.Line));
// Group elements that their indexes form a consecutive subsequence
מציאת מספרים בטקסט (בלי Regex)
איגוד ימי חופש רצופים של עובד
הבעיה היא בעיה שיחסית קל לפתור ע"י קוד אימפרטיבי: נגדיר מבנה שמייצג תת-סדרה רצופה:
var disconsecutiveShifted = disconsecutive.Skip(1);
IEnumerable<ConsecutiveSubsequence> result =
disconsecutive.Zip
(disconsecutiveShifted,
(x, y) => new ConsecutiveSubsequence()
{
StartIndex = x.Next.Value,
EndIndex = y.Current.Value,
});
return result;
}
בעצם מה שאנחנו עושים זה יוצרים מהאינדקסים שהתקבלו במתודה, זוגות המייצגים אינדקסים עוקבים בסדרה, זאת באמצעות האופרטור Zip המקבץ לנו שתי סדרות לסדרה אחת. (הערה: אנחנו שמים null לפני האינדקס הראשון וnull בתור האינדקס האחרון, כדי שנוכל להתחשב גם באינדקסים בקצוות)
כעת אנחנו מחפשים איפה נשבר הרצף, כלומר את הזוגות שבהם האיבר הבא בסדרה, אינו שווה למספר העוקב של האיבר הנוכחי בסדרה. בעזרת מקומות אלה אנחנו יכולים לגלות איפה מתחילה ואיפה נגמרת תת סדרה רצופה!
איך? בזוג המייצג קפיצה, האינדקס הקטן הוא האינדקס בו נגמר הרצף הקודם, האינדקס הגדול הוא האינדקס בו מתחיל הרצף החדש. מצורף שרטוט להמחשה (התאים הצהובים הם הזוגות שמייצגים קפיצות)
לכן כדי למצוא את התת-סדרות הרצופות, מספיק לנו להסתכל על האיבר Next של איבר בזוג ועל האיבר Current של הזוג העוקב. זאת אנחנו עושים שוב אמצעות המתודה Zip, אבל הפעם גם באמצעות האופרטור Skip המדלג לנו על האיבר הראשון בסדרה, כדי שנקבל זוגות של איברים עוקבים.
חידה: מה סכום המספרים בשיר “אחד מי יודע”? (כולל חזרות)
תשובה: ובכן, אם מנתחים את השיר, הוא נראה ככה:
אחד מי יודע? אחד - אני יודע! אחד אלוהינו שניים מי יודע? שניים - אני יודע! שני לוחות הברית, אחד אלוהינו שלושה מי יודע? שלושה - אני יודע! שלושה אבות, שני לוחות הברית, אחד אלוהינו …
קיצר אנחנו רואים שבשורה ה$ n $ בשיר סכום המספרים הוא:
$ n + n + n + (n - 1) + (n - 2) + \dots + 1 $
שהסכום של זה שווה לפי הנוסחה לסדרה חשבונית של גאוס: $ \displaystyle{ 2n + \frac{n (n+1)}{2} } $. עכשיו צריך לסכום את כל השורות מ1 עד $ n $: כלומר צריך לסכום את $ \displaystyle{ 2k + \frac{k (k+1)}{2} } $ מ$ k = 1 $ עד $ n $.
איך עושים את זה?
טוב, כאן מגיע החלק האומנותי של והיצירתי של הטיפ - נעבור לבעיה אחרת שלכאורה לא קשורה:
בכמה דרכים אפשר לחלק $ n $ תפוזים ל$ k $ ילדים? (כלומר, לא משנה מי מקבל איזה תפוז, אלא משנה כמה תפוזים הוא מקבל)
נסמן מספר זה ב$ F(n,k)$, אז מתקיימת נוסחת הנסיגה:
$ F(n, k) = F(n, k - 1) + F(n - 1, k - 1) + F(n - 2, k - 1) + \dots + F(0, k - 1) $
אכן: נבחר את אחד הילדים: אם הוא קיבל $ 0 $ תפוזים, אנחנו צריכים לחלק $ n $ תפוזים ל $ k - 1$ ילדים, אם הוא קיבל תפוז אחד, אנחנו צריכים לחלק $ n -1 $ תפוזים ל$ k-1 $ ילדים וכו’. כל אפשרות כזאת מתאימה למחובר מתחילת הסכום ( $ F(n,k-1) $ מתאים לאפשרות שהילד שבחרנו קיבל 0 תפוזים, $ F(n-1,k-1) $ מתאים לאפשרות שהילד שבחרנו קיבל תפוז אחד וכו’)
מסתבר שאפשר לחשב את $ F(n,k)$ בצורה מפורשת:
ניקח את כל ה$ n $ תפוזים ונשים ביניהם $ k -1 $ מקלות של ארטיק. כעת בין כל שני מקלות נוצרת מחיצה, ובסה”כ נוצרות $ k $ מחיצות. הילד ה$ i $ יקבל את התפוזים שנמצאים במחיצה ה$ i $.
מספר הדרכים לשים $ k - 1 $ מקלות של ארטיק בין $ n $ תפוזים הוא $ F(n,k) = \binom{n + k - 1}{k-1}$ כאשר $ \binom{n}{k} $ הוא המקדם הבינומי.
נזכור שמתקיים
$ F(n, k) = F(n, k - 1) + F(n - 1, k - 1) + F(n - 2, k - 1) + \dots + F(0, k - 1) $
השימוש הראשון של AppDomain שנדבר עליו הוא הצורך הבא:
כאשר אפליקציה עולה היא טוענת קובץ app.config באופן דיפולטי:
לפי השם של הExecutable שמריץ את האפליקציה בתוספת config. (למשל MyApplication.exe.config).
לפי web.config במידה ואנחנו מוארחים בIIS
לפעמים עולה לנו צורך להעלות את האפליקציה שלנו עם app.config שונה מהapp.config הדיפולטי.
לדוגמה, האפליקציה WcfSvcHost.exe מקבלת בתור פרמטרים את הPath לdll של הService שאנחנו רוצים להריץ ואת הapp.config של הService שאנחנו מעוניינים להריץ. (זה מה שרץ כאשר אנחנו מריצים Wcf Service Library)
הנתון של הקובץ app.config שאיתו האפליקציה שלנו עובדת קשור לAppDomain שלנו וניתן לגשת אליו ככה:
יצא לי בזמן האחרון להיתקל בכמה בעיות שנגעו לAppDomainים.
נתחיל בלהסביר מהו AppDomain.
כאשר אפליקציה .netית שלנו עולה, יש איזשהו “מרחב” שבו היא חיה.
כדי להמחיש את המרחב הזה, נסתכל על מספר דוגמאות
באפליקציה שלנו אנחנו יכולים לגשת למשתנים סטטיים. איפה משתנים אלה בדיוק נשמרים? שהרי בInstanceים אחרים של האפליקציה שלנו למשתנים האלה ערכים אחרים.
למי “שייכים” הThreadים של האפליקציה שלנו?
איך האפליקציה שלנו יודעת מאיפה לטעון DLLים?
התשובות לשאלות האלה כרוכות במושג של הAppDomain. הAppDomain הוא שכבה מבודדת שמהווה את המרחב של האפליקציה שלנו.
לרובנו לא יצא ליצור AppDomainים בעצמנו. כשהאפליקציה שלנו עולה, נוצר AppDomain דיפולטי עבורה בה היא רצה.
למעשה, זה לא מדויק:
כשאנחנו כותבים Process שהוא Stand-alone, כגון Console Application/Windows Form Application/WPF Application, אז נוצר באמת AppDomain דיפולטי יחיד עבורנו, בו האפליקציה שלנו חיה,
אבל לפעמים אנחנו לא כותבים Process שהוא Stand-alone, אלא מתארחים בProcess אחר. למשל, לפעמים אנחנו כותבים שירות WCF שמוארח על IIS. במקרה כזה הProcess שמריץ אותנו הוא הw3p.exe של IIS. במקרה כזה, הProcess שמארח אותנו מנהל את הAppDomainים שלו. במקרה של IIS, למשל, לכל שירות שהוא מארח, הוא פותח AppDomain נפרד (בערך), כך שבעצם אנחנו עובדים עם מספר AppDomainים בProcess יחיד.
עם זאת, לעתים נרצה להריץ יותר מAppDomain אחד באפליקציות שלנו, ועל כך נדבר בהמשך.